A design system that scores itself, and that a machine can build from
I rebuilt the Reliance Jewels design system end to end. Before drawing a component, I built a ruler: I scored the live product against its own brand promise, surface by surface. The most important screen in jewellery e-commerce scored 1 out of 5. That score is the case study.
- Role
- Product Designer: system + method, self-directed
- Surface
- RJ e-commerce, web, Vue 2 / Fynd
- Scope
- Audit → 39 components → eval method → AI layer
- Format
- .less tokens + live docs + Figma + manifest
- Problem
- The design system was a Figma UI kit with no reasoning behind any value, and the live product had drifted past trust: the most important page in jewellery e-commerce scored 1/5 against the brand's own promise.
- My move
- Three audits first (Figma, product, engineering), then a rebuild: 39 components with spec, code, docs and Figma in parity, 1346 tokens in three tiers, all policed by an automated quality gate.
- Outcome
- 39/39 components pass the gate, zero raw hex anywhere, and the system is machine-readable: a generated manifest plus hard constraints an AI can assemble new screens from without drifting.
- Learning
- Wire the gate into CI from day one, and pressure-test the AI layer on a genuinely new surface: the correction rate is the real measure of whether the system works.
Most designers have taste, but no ruler. I built the ruler first.
The premise of the whole project
Two broken things to fix, not one
Two things were broken: the design system, and the product it was supposed to be holding together.
A jewellery store carries unusual weight online. Nobody impulse-buys a ₹2 lakh necklace: they research, visit a showroom and come back a week later. The site's job is to extend the showroom, and to never once feel cheaper than it.
I had worked on these surfaces and watched them drift, one screen at a time. So I treated this as a self-directed rebuild: not a brief handed to me, a problem I could see and decided to solve properly.
The old system couldn't answer “why”. The product had drifted past trust.
The system couldn't justify a single value, and the flagship page scored 1 out of 5 on trust.
The existing system was a Figma UI kit, not a system. Audited component by component, the pattern was the same everywhere: a value with no reason behind it. The button had one of its five variants documented and zero interaction states. The icon “spec” was a screenshot of a plugin. Ask “why is the primary maroon the primary maroon” and the system had no answer.
Then I walked all nine live surfaces and scored each on two passes, functional and emotional. On a trust product, the emotional score is the one that matters.
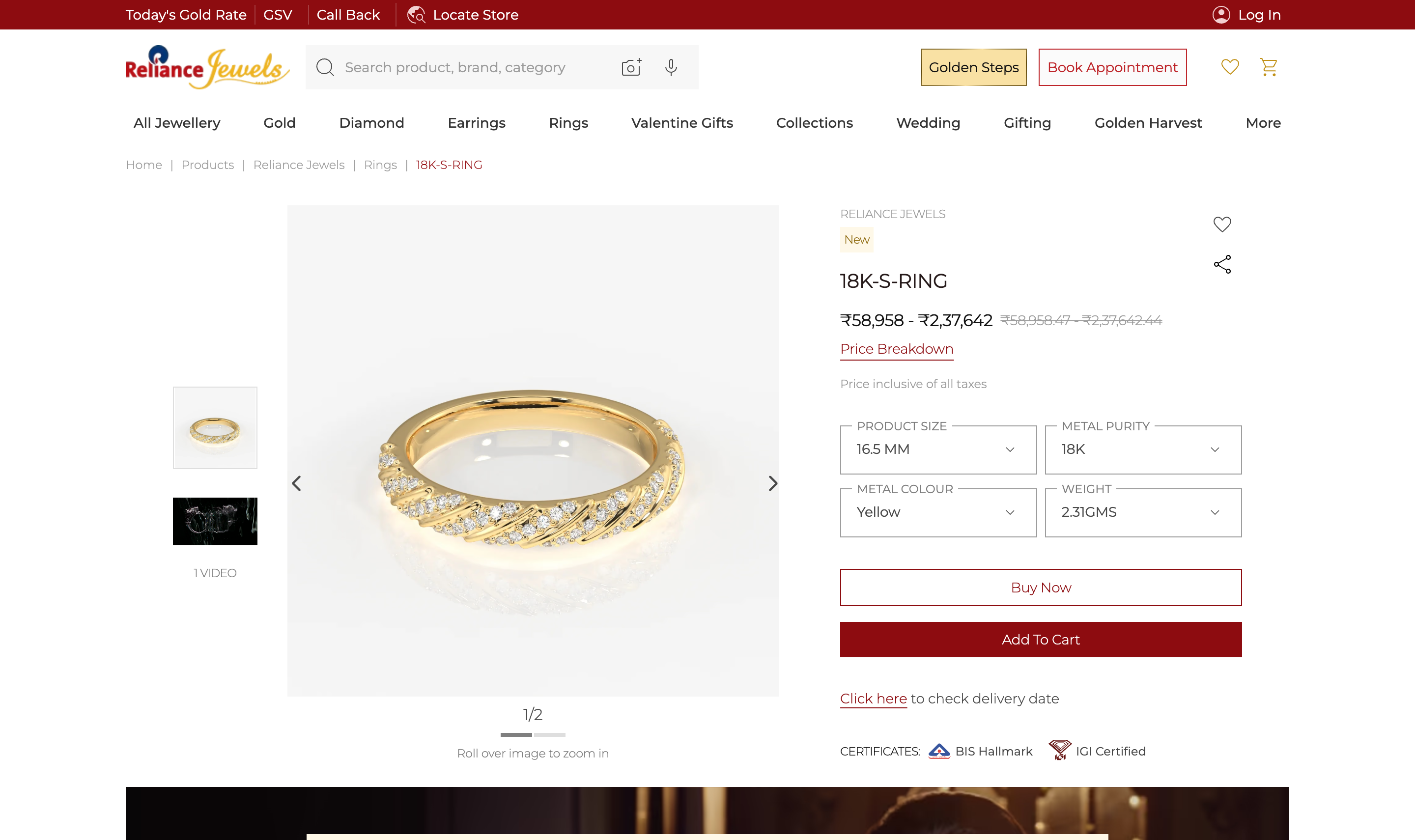
123- 1SKU code (“18K-S-RING”) shown where the product name belongs.
- 2A price-breakup table where every value is a dash.
- 3Buy Now and Add to Cart hierarchy inverted. No occasion, no story.
- PDP: SKU codes as names, dashes for prices
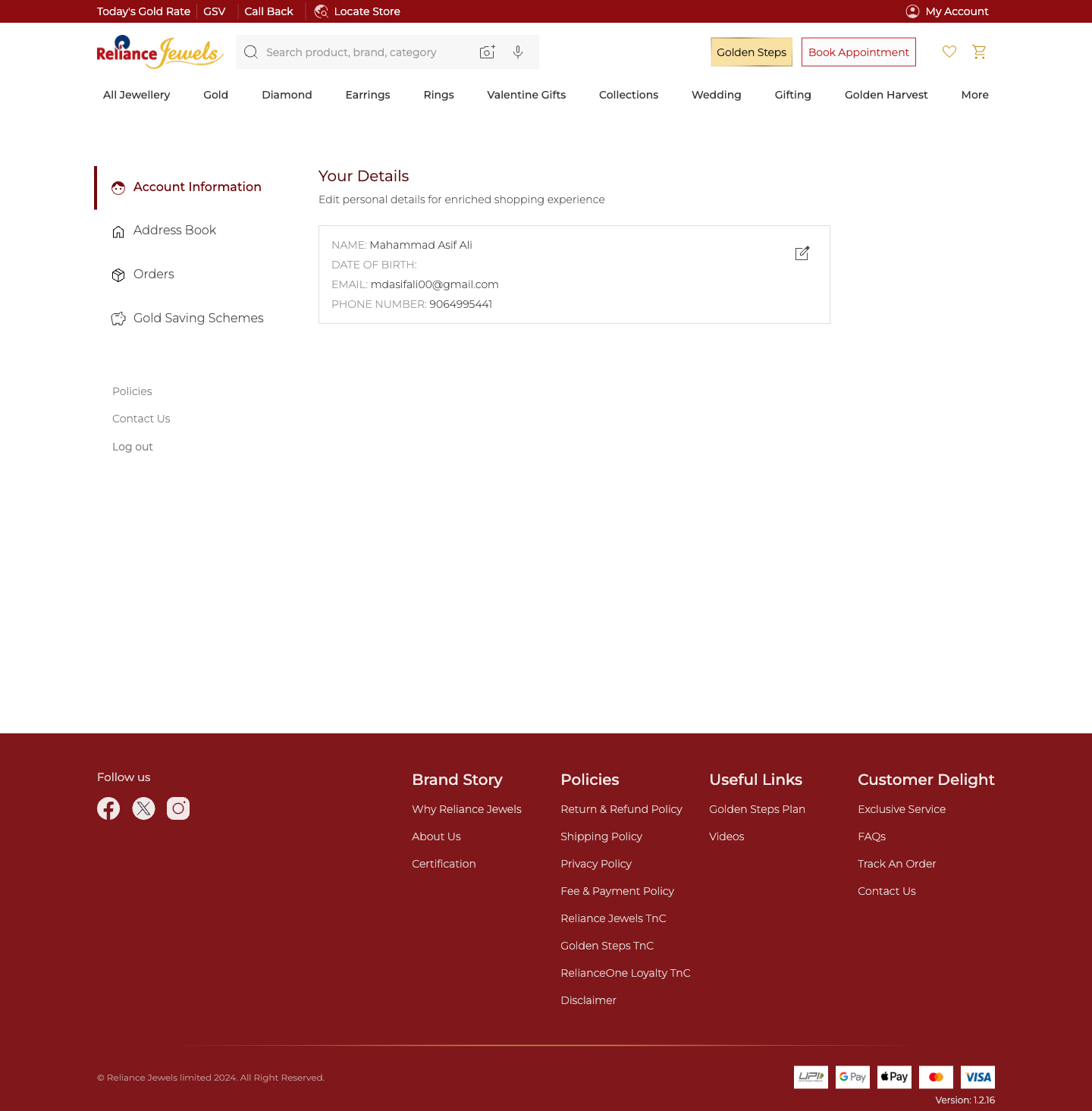
- My Account: two different layouts on one site
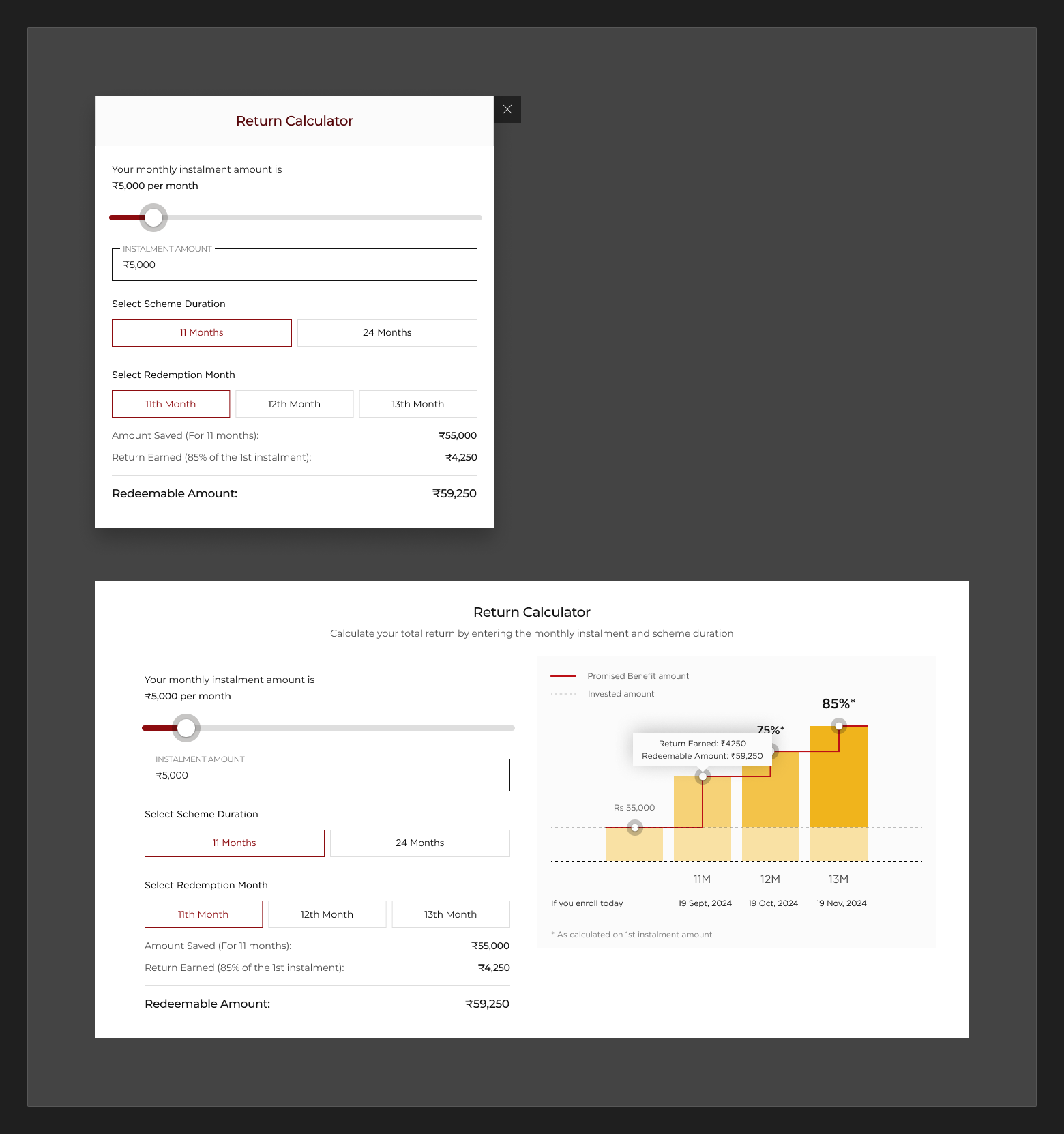
- GSS calculator: a bank form with a default browser slider
- On a jewellery store, inconsistency reads as carelessness
- Carelessness is the one thing a lakhs-spending buyer can't forgive
- The catalogue of failures became the build priority order

Three audits, not a moodboard
Three audits decided everything: the architecture, the priority order and the token format the build actually consumes.
Figma audit told me the first job was an architecture, not a reskin. Product audit gave me the priority order and the scoring rubric. Engineering audit decided the token format: Vue 2 on the Fynd engine compiles Less at build time, so the system had to be Less variables, because that is what the build actually consumes.
The bet underneath all of it: every value has to earn its place. If you cannot say why, it does not ship.
That one rule is what later made the system machine-readable.
Documentation as a function of code
Docs are generated from the code so they cannot drift, and no component ships a value it can't justify.
Three-tier tokens, no exceptions
Primitive holds raw values, semantic holds roles, component holds per-component tokens that reference semantics. Components never touch primitives. The non-negotiable rule: no hex, no raw pixel, no hard-coded string in any component file.
Generate the docs from the code, so they can't drift
A design system dies the day its docs drift from its code, so I removed the possibility. The .less is the single source of truth: a build script resolves the alias chain and emits the JSON and CSS that drive a live docs site, and Figma variable names mirror the .less names. Change the .less and everything follows. Hand-maintained docs always lose; generated docs stay honest with zero discipline required.
One vocabulary for “selected”
“Selected” now has exactly one language across the whole system. No component invents its own. The drift I started the audit with is now structurally impossible.
39 components. Each one is not done until it passes.
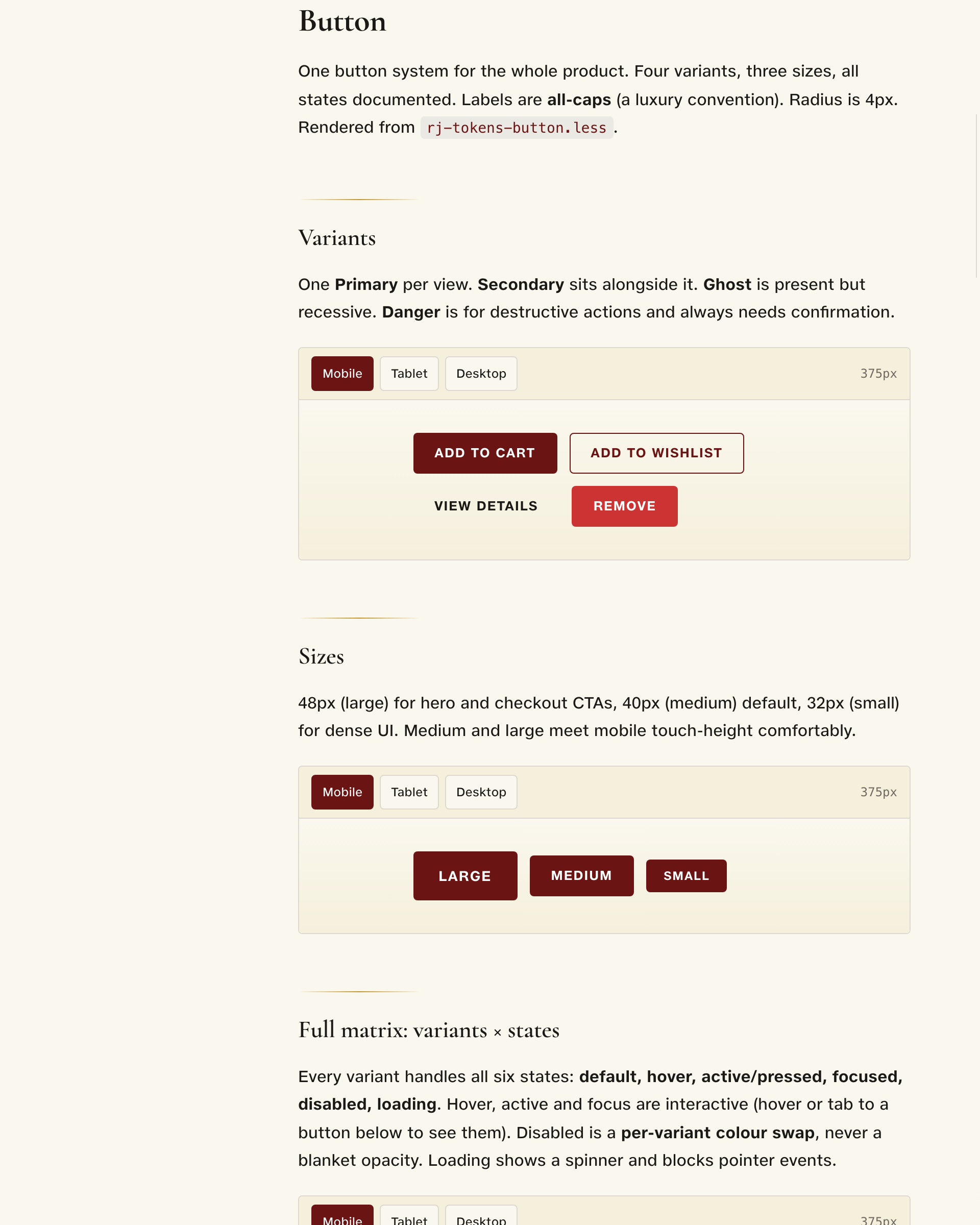
The before/after is concrete. The button went from one documented variant and no states to five variants across six states, fully tokenised. Icons went from a plugin screenshot to a 40-plus set with an engineering migration map. Every change carries its reason in the doc.
The docs are a live site, not Figma pages that drift. This is the button component, rendered from rj-tokens-button.less.
Two bars every screen has to clear. I published my own failing score.
I scored my own flows on the same bars and published the 2.4, with the fix plan attached.
- Feature parity against real product requirements
- Task-flow soundness, every state designed
- Cognitive load, microcopy, WCAG 2.2 AA
- A missing P0 feature is an automatic fail
- Restraint, hierarchy, type craft, colour discipline
- Material, depth, motion, imagery, finish
- Would this sit beside Cartier without apology?
- Average below 4.3 and it goes back
Components are the vocabulary. Flows are the sentences. I rebuilt real Reliance Jewels journeys entirely from documented components, on the phone where most customers are. Then I scored my own flows on the same two bars and published the scorecard with the weak numbers in it: the PDP flow scored 2.4 on UX. I wrote the fix plan in priority order rather than hiding the gap.
The part I'm most willing to show a hiring manager is the scorecard that proves I can't quietly lower my own bar.
A system a machine can build from, without drifting
The whole system in one generated file: token groups, all 39 components with problems, variants, states and rules. Regenerates on every build, so it never drifts.
Explicit, checkable rules. Most are enforced by the same quality gate.
Tells a model to reuse before creating, use only tokens, honour the one active language, and flag a missing token instead of inlining a literal.
A complete system, safe to evolve, legible to a machine
A complete, gate-enforced system a machine can build from, honest about not yet being rolled out.
The hard calls were deliberate. I held tokenisation, state matrices, accessibility and the active language to a non-negotiable bar, and accepted “good enough” on visual flourish so the project could finish. Knowing where not to gold-plate is part of the job.
Honest on adoption: the system is built, not yet rolled out across the live store. That is the next phase, not a claim I am making here.
What I'd do differently
Wire the gate into CI from day one, and measure the AI's correction rate on a genuinely new surface.
If I ran it again, I would wire the gate into CI on the product repo from day one, so a component that breaks token discipline cannot merge. I would run an adoption pass surface by surface against the live store. And I would pressure-test the AI layer harder: have it assemble a genuinely new surface end to end and measure how much I have to correct. That correction rate is the real measure of whether the system works, and I want the number.